分布式
# CAP&BASE
# CAP
# Consistency
(一致性)
所有节点访问同一份最新的数据副本
# Availability
(可用性)
非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应)
# PartitionTolerance
(分区容错性)
分布式系统出现网络分区的时候,仍然能够对外提供服务
不是三选二,分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构
# CP(强一致性)
# Zookeeper
任何时刻对 ZooKeeper 的读请求都能得到一致性的结果
# HBase
# AP(可用性)
# Eureka
Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况
Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了,只不过这个节点上的数据可能并不是最新的
# Cassandra
# CP&AP
# Nacos
# BASE
# BasicallyAvailable
(基本可用)
指分布式系统在出现不可预知故障的时候,允许损失部分可用性
响应时间上的损失
正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s
系统功能上的损失
由于系统访问量突然剧增,系统的部分非核心功能无法使用
# Soft-state
(软状态)
指允许系统中的数据存在中间状态(CAP 理论中的数据不一致),并认为该中间状态的存在不会影响系统的整体可用性,
允许系统在不同节点的数据副本之间进行数据同步的过程存在延时
# EventuallyConsistent
(最终一致性)
系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态
# 思想
即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性
是对 CAP 中 AP 方案的一个补充
没分区,不存在P,保证AC,发生分区,CP或者AP,AP 方案只是在系统发生分区的时候放弃一致性,而不是永远放弃一致性,在分区故障恢复后,系统应该达到最终一致性
# Paxos 算法
一种解决分布式系统一致性的经典算法,被公认的非常难以理解和实现
实现是一致性状态机
# Leader选举
# Raft 算法
共识算法就是保证一个集群的多台机器协同工作,在遇到请求时,数据能够保持一致。
Leader election 领导选举
领导者,跟随者,候选者
Log replication 日志复制
Safety 安全性
# 优点
# 强一致性
虽然所有节点的数据并非实时一致,但Raft算法保证Leader节点的数据最全,同时所有请求都由Leader处理,所以在客户端角度看是强一致性的
# 高可靠性
Raft算法保证了Committed的日志不会被修改
# 高可用性
Leader故障,在选举超时到期后,集群自发选举新Leader
Leader故障时存在重复数据问题,需要业务去重或幂等性保证
# 高性能
必须将数据写到所有节点才能返回客户端成功的算法相比,Raft算法只需要大多数节点成功即可
# ZAB协议
(ZooKeeper Atomic Broadcast 原子广播)
为分布式主备系统设计
为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议
在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性
崩溃恢复
当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器
消息广播
集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了
# 具体到组件
# etcd
使用Raft算法,比较currentTerm,三个状态Leader、Follower、Candidate
# Redis 的 Sentinel
使用 Raft 算法
# kafka
通过ZK来实现选举,通过ZK来实现选举
# zk
使用ZXID、myid来选举,ZAB协议,Leader、Follower,超过半数,选举(崩溃恢复)和同步数据(消息广播)
# 一致性
是指对每个节点一个数据的更新,整个集群都知道更新,并且是一致的
# 强一致性
系统写入了什么,读出来的就是什么
# 弱一致性
不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态
# 最终一致性
系统会保证在一定时间内达到数据一致的状态
# 实现的方式
# 读时修复
在读取数据时,检测数据的不一致,进行修复
# 写时修复
(推荐,对性能消耗比较低)
在写入数据,检测数据的不一致时,进行修复
# 异步修复
最常用的方式,通过定时对账检测副本数据的一致性,并修复
# 分布式事务
# 强一致性事务
(只能用在数据库层面)
# 2PC
(Two-phase commit protocol)
# 准备阶段
(投票阶段)
提议的节点称为协调者(coordinator)
参与决议节点称为参与者(participants, 或cohorts)
# 提交阶段
(执行阶段)
如果参与者全部同意则提交,只要有一个参与者不同意就中止
对一条数据的修改操作首先写undo日志,记录的数据原来的样子,接下来执行事务修改操作,把数据写到redo日志里面
undo与redo能保证数据的强一致性
# 优点
原理简单,实现方便
# 缺点
# 同步阻塞
二阶段提交的过程中,所有的节点都在等待其他节点的响应
# 单点问题
如果协调者在提交阶段出现问题,那么整个流程将无法运转
# 数据不一致
局部网络异常或协调者在尚未发送完所有 commit请求之前自身发生了崩溃
只有部分参与者收到了commit请求,这将导致严重的数据不一致问题
# 容错性不好
二阶段提交协议没有设计较为完善的容错机制,任意一个节点是失败都会导致整个事务的失败
# 3PC
引入超时机制
# canCommit
2pc的准备
# PreCommit
# doCommit
有任何一个参与者向协调者发送了No响应,或者等待超时之后,执行事务的中断
# 与2pc区别
第二阶段才写undo和redo事务日志
第三阶段协调者出现异常或网络超时参与者也会commit
# 优点
改善同步阻塞
改善单点故障
# 缺点
同步阻塞
单点故障
数据不一致
容错机制不完善
# 补偿性事务思想
TCC
# 最终一致性事务
本地消息表
消息事务
最大努力通知
# 分布式锁
场景:互联网秒杀,抢优惠卷,接口幂等性校验
# 基于数据库
# 基于Redis
SETNX
SET if Not eXists
key 不存在则set成功返回 1,如果这个key已经存在了返回0
SET key value [EX seconds|PX milliseconds] [NX|XX] [KEEPTTL]
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
String lockKey = "product_001";
try{
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey,"wangcp",10,TimeUnit.SECONDS);
if(!result){
// 代表已经加锁了
return "error_code";
}
// 从redis 中拿当前库存的值
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}else{
System.out.println("扣减失败,库存不足");
}
}finally {
// 释放锁
stringRedisTemplate.delete(lockKey);
}
return "end";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
SETEX
SETEX key seconds value
key 已经存在,setex命令将覆写旧值
setex是一个原子性(atomic)操作
# RedLock
Redis官方提出的一种分布式锁的算法
- 顺序向n个节点请求加锁
- 根据一定的超时时间来推断是不是跳过该节点
- (n/2+1)节点加锁成功并且花费时间小于锁的有效期
- 认定加锁成功
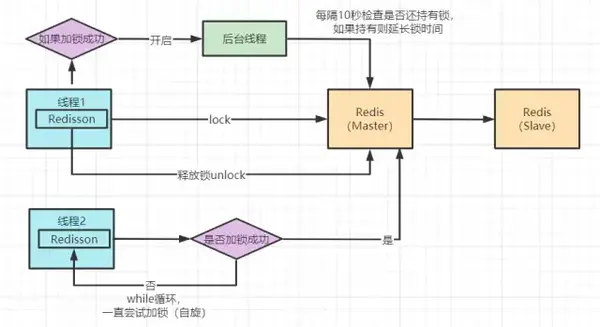
# Redisson分布式锁
@Bean
public RedissonClient redisson(){
// 单机模式
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.3.170:6379").setDatabase(0);
return Redisson.create(config);
}
2
3
4
5
6
7
@RestController
public class IndexController {
@Autowired
private RedissonClient redisson;
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 模拟下单减库存的场景
* @return
*/
@RequestMapping(value = "/duduct_stock")
public String deductStock(){
String lockKey = "product_001";
// 1.获取锁对象
RLock redissonLock = redisson.getLock(lockKey);
try{
// 2.加锁
redissonLock.lock(); // 等价于 setIfAbsent(lockKey,"wangcp",10,TimeUnit.SECONDS);
// 从redis 中拿当前库存的值
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock",realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
}else{
System.out.println("扣减失败,库存不足");
}
}finally {
// 3.释放锁
redissonLock.unlock();
}
return "end";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 基于Zookeeper
# 分布式ID
# 高并发
# 消息队列
# 缓存
# 读写分离&分库分表
# 负载均衡
# 算法
# 轮询(Round Robin)
# 随机(Random)
# 加权
# 最小连接数
# hash
# 一致性Hash
环形Hash空间
把数据通过一定的hash算法处理后映射到环上
将机器通过hash算法映射到环上
机器的删除与添加
平衡性
“虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品( replica )
# Nginx
# 轮叫
# 权重轮叫
# 最小连接
# 权重最小连接
# Dubbo
随机
轮询
活跃度
Hash一致性